AI侦探崛起;匿名发言不再安全,真实身份几分钟内显露。


想象一下,你在论坛上匿名吐槽工作、分享兴趣,却没想到这些随意的话语正成为别人手中的线索。近年来,人工智能尤其是大型语言模型的出现,让网络匿名性遭受前所未有的冲击。研究人员通过实验证明,只需提供少量匿名帖子,AI就能在短时间内推断出用户的大致身份。这种转变速度之快、门槛之低,令人警醒。
这项来自知名学府与AI企业的联合研究,聚焦于如何利用大模型实现规模化身份重识别。他们设计出一套完整流程:从文本中挖掘身份相关特征,使用语义匹配寻找候选,再通过推理确认最佳匹配,并校准置信度。在HackerNews与LinkedIn的跨平台测试中,这种方法展现出显著优势,能够在保持较高精确率的前提下,覆盖相当比例的目标用户。传统方式在类似场景下几乎无从下手。

为什么AI如此强大?关键在于它模拟人类阅读与推理的过程。过去人工追踪需要耗费大量时间翻阅资料、比对细节,而现在模型可以自动化完成这些步骤,甚至同时处理多个账户。用户随口提到的电影偏好、职业习惯或地域特色,都可能被整合成独特画像。实验数据显示,当用户分享内容增多时,识别成功率会明显上升,这说明在线活跃度越高,隐私泄露风险越大。
更令人担忧的是,这种技术成本相对较低,操作简便。研究中提到的数据集包括电影社区讨论、时间拆分的Reddit历史,以及问卷调查记录等。即便在信息有限、非结构化的情况下,AI也能从中提取线索,实现身份关联。这颠覆了以往对匿名的信心——人们以为散落的信息难以拼凑,却忽略了AI的强大归纳能力。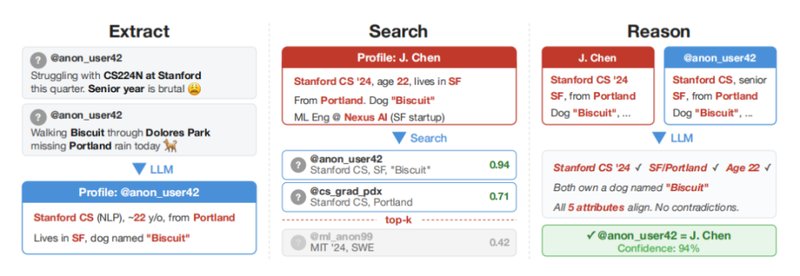
研究者警告,互联网隐私正迎来新拐点。匿名曾鼓励自由表达,但如今任何痕迹都可能指向真实个体,导致潜在的骚扰或信息滥用。平台虽有防护措施,但技术进步要求更主动的应对策略。用户也需提升意识,审慎选择分享内容,避免将可追踪元素暴露在外。
回顾历史,早年Netflix数据集的去匿名化事件已敲响警钟,而如今大模型将威胁扩展到自由文本领域。未来,隐私保护可能需要结合技术与政策,如改进匿名机制、限制模型滥用等。只有多方协作,才能缓解这一新兴风险,维护网络空间的相对安全与开放。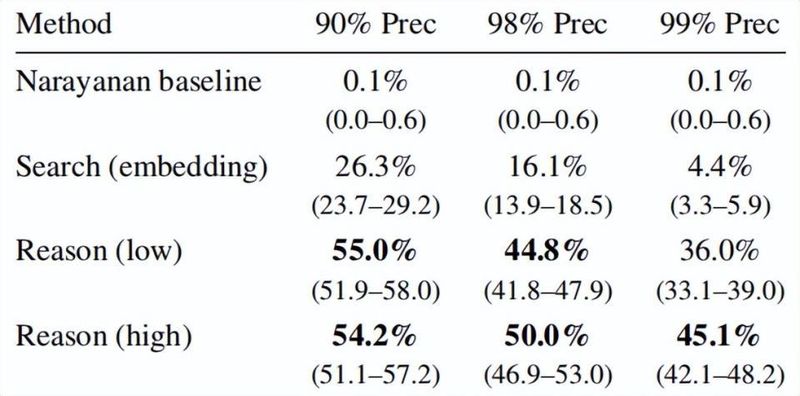
总之,这项发现提醒我们,技术双刃剑特性愈发明显。在享受AI便利的同时,必须正视其对隐私的冲击。通过持续关注与改进,我们有望在创新浪潮中守护个人边界,让网络世界继续成为思想碰撞的自由场所。